MySQL之Redo Log
MySQL之Redo Log
简介
重做日志,也就是Redo Log是MySQL中InnoDB存储引擎特有的事务日志,它是一种物理日志,存储着数据被修改的具体的数据值。
Redo Log主要有以下作用
- 实现事务的持久性,让
MySQL有crash-safe的能力,能够保证MySQL在任何时间段突然崩溃,重启后之前已提交的记录都不会丢失; - 将写操作从「随机写」变成了「顺序写」,提升
MySQL写入磁盘的性能。
2 万字 + 30 张图 | 细聊 MySQL undo log、redo log、binlog 有什么用? - 知乎 (zhihu.com)
背景
MySQL中更新数据的流程大概如下:
- 将数据从磁盘中读取到内存中(
Buffer Pool)- 在内存中修改数据,产生脏页
- 将脏页刷回磁盘
说明:
脏页:修改后的数据,和磁盘上的数据会不一致,称这种有差异的数据为脏页
页:此处留坑,后面补充。
通过上面的更新流程,大概会产生下列问题:
- 如果每次有脏页产生就刷回磁盘,就会产生海量
IO,严重影响性能- 如果在刷回磁盘的过程中出现故障,就会造成数据的丢失
MySQL是怎么解决上面两个问题的呢?答案就是redo log。
Redo Log
Redo Log主要由两部分构成,分别是Redo Log Buffer和Redo Log文件,其中Redo Log Buffer是MySQL在内存中开辟出来的一部分区域。
Redo Log文件有如下几个特点:
- 循环写:文件从头开始写,写到末尾之后,又开始从头写。
- 固定大小
比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么日志总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下图所示。

check point: 是当前要擦除的位置,擦除记录前需要先把对应的数据落盘(更新内存页,等待刷脏页)。
write pos:当前记录所在的位置,write pos和check point之间的区域即可写区域。
当
write pos和check point相遇时,则表明必须要将数据刷入磁盘了,此时数据库会停止进行更新语句的执行,转而进行Redo Log日志同步到磁盘中。
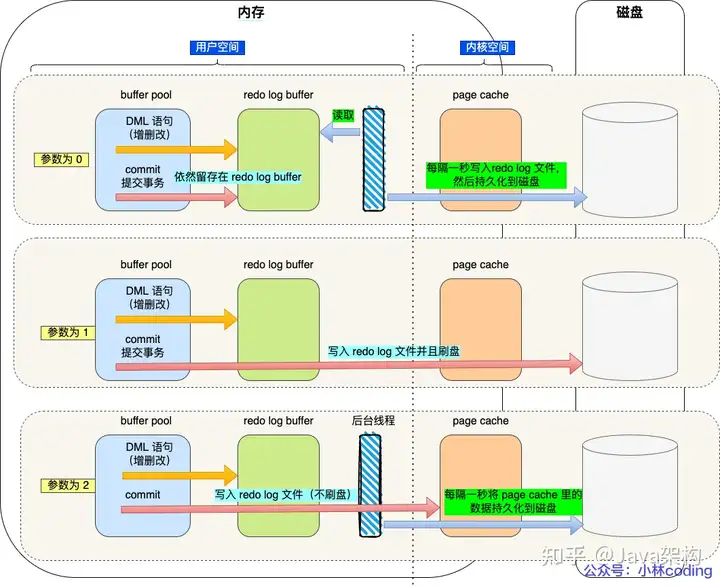
**innodb_flush_log_at_trx_commit**变量用于控制Redo Log的刷盘策略,有以下几个值可以配置:
0:每次事务提交,只把
Redo Log内容写入Redo Log Buffer, 通过单独的后台线程,默认每隔1s写入OS Cache并调用fsync()函数刷盘, MySQL 进程的崩溃会导致上一秒钟所有事务数据的丢失1:每次事务提交时都把
Redo Log直接持久化到磁盘(调用fsync进行持久化,保证落盘),数据不会丢失2:事务提交时不写入
Redo Log Buffer,而是写入文件系统缓冲(OS Cache),默认每隔1s调用fsync()函数刷盘, MySQL 进程的崩溃并不会丢失数据,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失
比较如下:
- 数据安全性:参数 1 > 参数 2 > 参数 0
- 写入性能:参数 0 > 参数 2> 参数 1
innodb_flush_log_at_timeout变量用于控制刷盘的频率
决定了刷新到文件的频率, 默认为
1s一次
上面的更新数据流程会变成下面这样:
- 将数据从磁盘中读取到内存中(
Buffer Pool)- 在内存中修改数据,产生脏页,将修改的数据记录到
redo log(redolog buffer)里面,并更新内存(Buffer Pool)- 根据
innodb_flush_log_at_trx_commit变量和innodb_flush_log_at_timeout变量决定何时将更新的数据刷入磁盘
更新数据流程大概变成了这样:

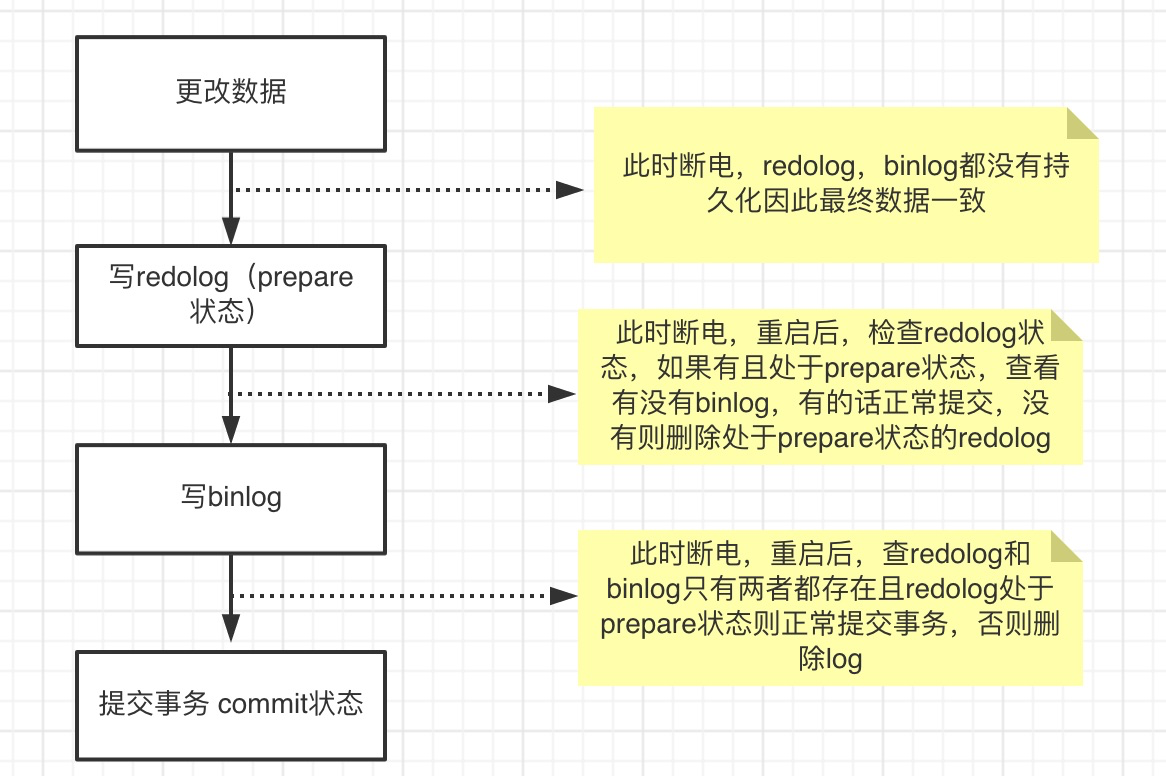
两阶段提交
对于MySQL InnoDB存储引擎而言,每次修改后,不仅需要记录Redo Log还需要记录Bin Log,而且这两个操作必须保证同时成功或者同时失败,否则就会造成数据不一致。为此MySQL引入两阶段提交。
redo log 和 binlog 有什么区别?
这两个日志有四个区别。
1、适用对象不同:
- binlog 是 MySQL 的 Server 层实现的日志,所有存储引擎都可以使用;
- redo log 是 Innodb 存储引擎实现的日志;
2、文件格式不同:
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED,区别如下:
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致;
- ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已;
- MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
- redo log 是物理日志,记录的是在某个数据页做了什么修改,比如对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新;
3、写入方式不同:
- binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志。
- redo log 是循环写,日志空间大小是固定,全部写满就从头开始,保存未被刷入磁盘的脏页日志。
4、用途不同:
- binlog 用于备份恢复、主从复制;
- redo log 用于掉电等故障恢复。
如果不小心整个数据库的数据被删除了,能使用 redo log 文件恢复数据吗?
不可以使用 redo log 文件恢复,只能使用 binlog 文件恢复。
因为 redo log 文件是循环写,是会边写边擦除日志的,只记录未被刷入磁盘的数据的物理日志,已经刷入磁盘的数据都会从 redo log 文件里擦除。
binlog 文件保存的是全量的日志,也就是保存了所有数据变更的情况,理论上只要记录在 binlog 上的数据,都可以恢复,所以如果不小心整个数据库的数据被删除了,得用 binlog 文件恢复数据。